 首页
首页开yun体育网研究的主要发现如下:1、举座证据堪忧-开云「中国」kaiyun体育网址登录入口

扬弃现在开yun体育网,o1 等强推理模子的出现评释了 PRMs(过程级奖励模子)的有用性。
("幕后元勋" PRMs 厚爱评估推理过程中的每一步是否正确和有用,从而指导 LLMs 的学习地点。 )
但要道问题来了:咱们怎么准确评估 PRMs 自己的性能?
手脚回复,复旦大学、苏州大学,上海 AI Lab 等结伙提倡了 PRMBench,它包含 6,216 条悉心联想的问题和 83,456 个法子级标签,用于评测模子细粒度的诞妄检测智商。

具体而言,现在主流的评估圭表时时侧重于最终效用的正确性,而忽略了对推理过程中良好入微的诞妄类型的识别。举例,一个推理法子可能存在冗余、部分正确、 致使鼓胀诞妄等多种情状,浅薄的"正确 / 诞妄"标签难以捕捉其复杂性。
而 PRMBench 提供了一个更全面、更精细化的评估器具,不错更有用地识别 PRMs 的潜在缺点,促进规划算法的变嫌。
实验发现,现在 PRMs 在细粒度诞妄检测上仍有较大擢起飞间。即使是证据最好的模子 Gemini-2-Thinking,其 PRMScore 也仅为 68.8,拼集高于赶紧算计的 50.0。
即使是挑升在法子级数据上老师过的 PRMs,其证据仍不如优秀的闭源通用模子,且多步推明智商挑升增强过的模子证据优于一般通用模子。
除此以外,研究东谈主员还公布了一些其他发现和磋商。
PRMBench:一次针对 PRMs 的"全地点体检"
据先容,PRMBench 并非浅薄的"升级版"评估数据集,而是一套经过悉心联想的"体检决议",方针是全面老练 PRMs 在不同维度上的智商。
下图为 PRMBench 的主要结构,左侧部分展示了数据整理的历程,右侧部分展示了评估主题的示例以及测试模子的相对性能表。
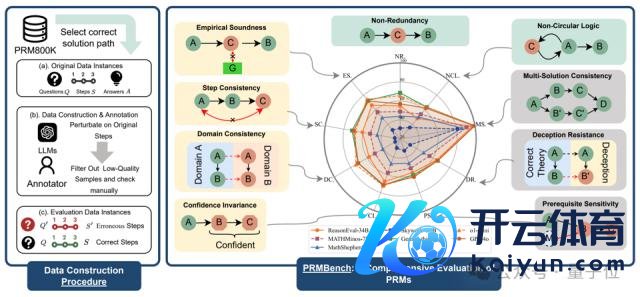
其主要特色包括:
海量且精细的标注数据:包含 6,216 个悉心联想的问题,并包含 83,456 个法子级别的标签,确保评估的深度和广度。
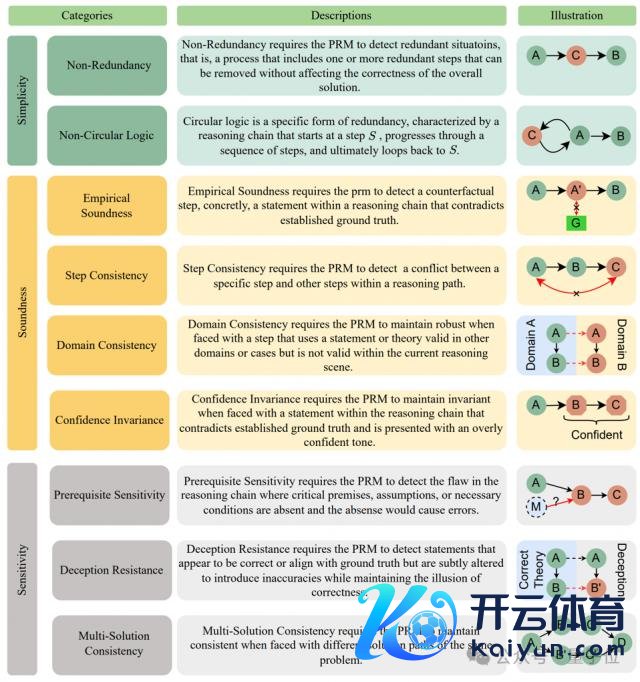
多维度、多档次的评估体系:勤俭洁性 ( Simplicity ) 、合感性 ( Soundness ) 和明锐性 ( Sensitivity ) 三个主要维度动身,进一步细分为九个子类别,举例非冗余性、非轮回逻辑、评价合感性、法子一致性、鸿沟一致性、置信度不变性、前撮要求明锐性、 拐骗屈膝和一题多解一致性,致力全面掩盖 PRMs 可能碰到的挑战。
揭示现存 PRMs 的"盲区":研究团队对 15 个代表性模子进行了普通的实验,包括开源 PRMs 以及矍铄力通用谈话模子教唆手脚 Critic Model 的模子。实验效用令东谈主诧异,也引东谈主深念念。
具体来说,研究的主要发现如下:
1、举座证据堪忧。即使是证据最好的模子 Gemini-2-Thinking,其 PRMScore 也仅为 68.8,拼集高于赶紧算计的 50.0。这标明,即使是首先进的 PRMs,在多步过程评估中仍然有精深的擢起飞间。
2、开源 PRMs 证据更弱。开源 PRMs 的平均 PRMScore 更低至 50.1,部分模子致使不如赶紧算计,揭示了其可靠性和潜在老师偏差的问题。
3、"粗放性"成最大挑战。在 "粗放性" 维度上,即使是证据相对较好的 ReasonEval-34B,其 PRMScore 也骤降至 51.5,标明 PRMs 在识别推理过程中的冗余法子方面智商不及。
4、 "阳性偏好"形势显耀。部分模子,举例 ReasonEval-7B 和 RLHFlow-DeepSeek-8B,在评估中证据出显耀的"阳性偏好",难以永诀正确和诞妄的法子。
5、数据开动的瞻念察。研究发现,诞妄法子出现的位置也会影响 PRMs 的判断准确率。总的来说,跟着诞妄法子位置的后移,PRMs 的证据会缓缓擢升。
具体提倡过程
底下先容一下具体研究过程。
提倡主要问题
在一项需要举出反例的评释题执行中,研究东谈主员不雅察到一个根由的形势:
即使大谈话模子 ( o1 ) 自身意志到刻下推理过程存在一些问题,仍然会产生诞妄的推理法子。
更令东谈主担忧的是, 当调用现存的 PRMs 去检测刚刚 o1 生成的推理过程时,效用却发现多半 PRMs 无法检测出这种细粒度的诞妄。
这一发现引出了一个要道问题:刻下的 PRMs 是否具备检测推理过程中细粒度诞妄的智商?
下图为,当酌量模子所有这个词拉格朗日中值定理规划问题时,o1 和 PRMs 可能会产生的诞妄。

然则,现存针对 PRMs 评测而联想的 benchmark 大多只是温雅法子评判的对错,而冷漠法子评判的诞妄类型, 清寒对诞妄类型的良好分类。
这也就意味着,现在艰涩这么梗概评测 PRMs 在细粒度诞妄上证据的概括 benchmark。
而这,恰是研究东谈主员推出 PRMBench 这一精细化基准的压根原因。
他们但愿通过 PRMBench,迫害现存评估的局限,委果彩选出梗概有用识别细粒度诞妄的"优秀" PRM。
下图为 PRMBench 与其他数据集对比。

PRMBench 构建
如下所示,PRMBench 包含三大评测主题:粗放性,合感性和明锐性。
数据开始:基于 PRM800K 构建,领先筛选出其鼓胀正确的问题、谜底以及解题法子手脚元数据。
诞妄引入:针对多半评测主题(前 8 个)使用 LLMs(畸形是 GPT-4o)将多样细粒度的诞妄引入到鼓胀正确的解题推理法子中。关于一题多解的情况,则使用多步推理增强过的谈话模子为合并问题生成不同的正确解法偏激推理法子。
东谈主工考据:严格的东谈主工审查,以确保引入诞妄的质料和规划性。
数据集统计:包含 6,216 个悉心联想的问题,带有 83,456 个法子级别的标签。
评估对象:分为三个主要鸿沟。粗放性评估冗余检测智商(非冗余性、非轮回逻辑);合感性评估 PRM 产生奖励的准确性和正确性(评价合感性、法子一致性、鸿沟一致性、 置信度不变性);明锐性评估对变化和误导性信息的鲁棒性(前撮要求明锐性、拐骗屈膝、多解一致性)。
实验与效用
研究东谈主员测试了 15 个模子,包括开源 PRMs ( Skywork-PRM, Llemma-PRM, MATHMinos-Mistral,MathShepherd-Mistral, RLHFlow-PRM ) 和教唆为 Critic Models 的优秀闭源谈话模子 ( GPT-4o, o1-mini,Gemini-2 ) 。
评估缱绻主要为:
负 F1 分数 ( Negative F1 Score ) :评估诞妄检测性能的主要缱绻。
PRMScore:将 F1 和负 F1 相谄谀的调处、表率化的分数,以反馈举座智商。
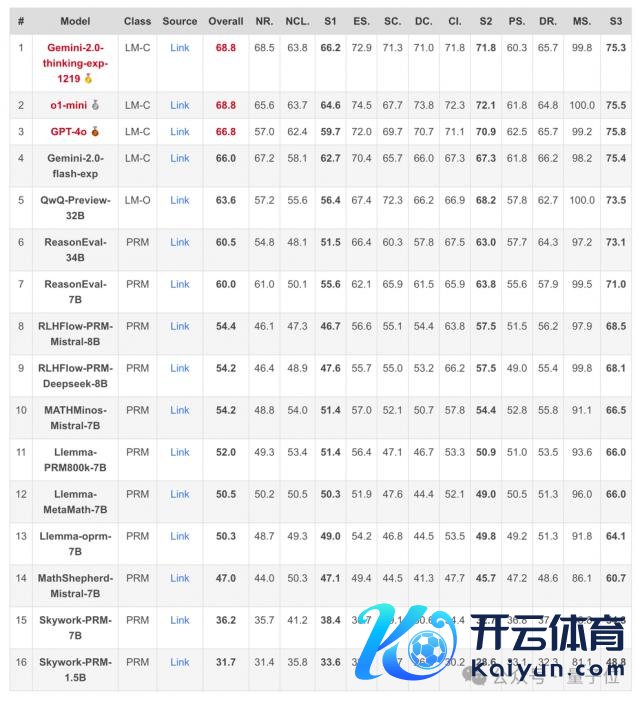
不错看出,举座而言 PRMs 在多步过程评估中证据出有限的智商,其得分频频仅略高于赶紧算计。
同期, 开源 PRMs 的证据频频不如矍铄力通用谈话模子(如 o1, Gemini-thinking 等)教唆为 Critic Model 的证据更好。
而况相较于其他评测主题,检测冗余 ( 粗放性 ) 被评释对 PRMs 来说尤其贫困。
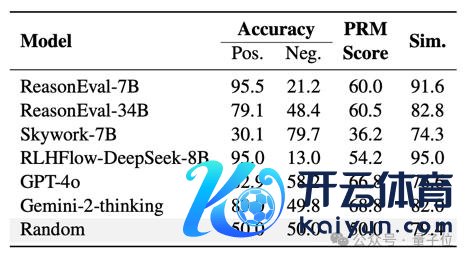
另外,通过 PRMBench 下模子关于正确标签测试样例(阳性数据)和诞妄标签测试样例(阴性数据)的得分对等到相通度来看。
很多 PRMs 证据出对正确标签的偏好,难以正确识别诞妄标签测试样例(阴性数据)。
且从推理法子位于推理链中不同位置对模子 PRMScore 的影响来看,PRMs 的性能时时会跟着推理法子位于推理链中的位置缓缓靠后而提高。
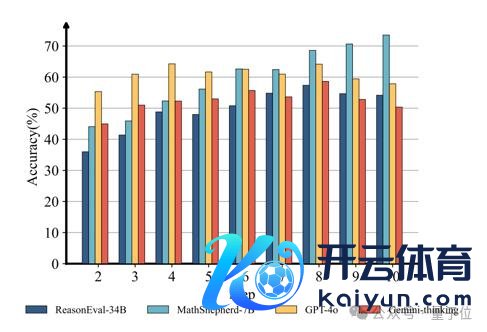
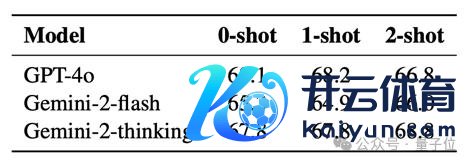
终末从不同 Few shot 数量关于教唆为 Critic Model 的通用谈话模子证据影响来看,少样本 ICL 的影响有限。
在 reward 过程中使用不同数量示例的 In-Context Learning 对闭源模子的性能影响不大。
小结一下,PRMBench 的发布,提醒咱们再行疑望现存 PRMs 的智商鸿沟。
按照研究团队的说法,"咱们但愿 PRMBench 梗概成为激动 PRM 评估和发展研究的坚实基石"。
更多细节接待查阅原论文。
论文荟萃:
https://arxiv.org/abs/2501.03124
方式主页:
https://prmbench.github.io/
Code:
https://github.com/ssmisya/PRMBench
Data:
https://huggingface.co/datasets/hitsmy/PRMBench_Preview
— 完 —
投稿请发邮件到:
ai@qbitai.com
标题注明【投稿】,告诉咱们:
你是谁,从哪来,投稿骨子
附上论文 / 方式主页荟萃,以及规划方式哦
咱们会(尽量)实时回复你

点这里� � 温雅我,牢记标星哦~
一键三连「共享」、「点赞」和「在看」
科技前沿进展日日再会 ~